
Everything You Should Know About Apache Kafka and 아파치 카프카 사용법
Apache Kafka is a viable alternative to a traditional messaging system. It began as an internal system created by Linkedin to manage 1.4 trillion daily messages. However, today it’s an open-source data streaming system that can meet a range of business requirements.
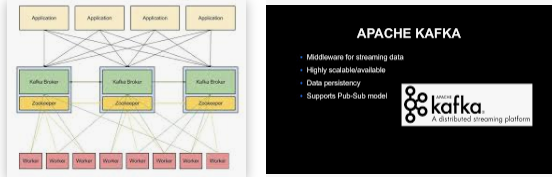
Apache Kafka is an open data store designed to process and ingest streaming data in real-time. Streaming data is constantly generated by various data sources that generally send data records simultaneously. Therefore, a streaming platform must cope with this continuous flow of data and process the data incrementally and in a sequence.
Apache Kafka has three primary purposes for its users:
- Create and subscribe to streams of records
- Effectively save streams of records in the order that records were created.
- Process records into streams in real-time
Apache afka is used primarily to create real-time streaming data pipelines as well as applications that can adapt to a stream of data. It blends storage, messaging and stream processing to enable the storage and analysis of real-time and historical data.
Why would you want to use Apache Kafka?
Kafka can create real-time streaming pipelines for data and applications that stream in real-time. Data pipelines are reliable in processing and transferring the data between one device and the next, and a streaming app can be described as an app that consumes a stream of data. For instance, if you would like to develop a data pipeline that takes the data from user activity to monitor how users browse your site in real-time. Apache Kafka would be used to store and ingest streaming data and serve readings to the applications that run your data pipeline. Kafka is also frequently utilized as a message broker that acts as an infrastructure that handles and facilitates communication between two apps.
Apache Kafka function 아파치 카프카 사용법
Kafka incorporates two messaging models that are queuing and publish-subscribe, delivering the main benefits of both to users. Queuing enables the processing of data to spread across multiple instances of the consumer, making it extremely flexible. But traditional queues aren’t multi-subscriber. The approach of publishing-subscribe is multi-subscriber. However, since every message goes to each subscriber, it can’t spread work across different worker processes. Apache Kafka utilizes the partitioned log model to connect both of these solutions. Logs are an ordered sequence of records. The logs are divided into partitions or segments corresponding to different subscribers. There may be many subscribers to a similar topic, and each one is assigned a separate division that allows for greater capacity. Additionally, Kafka’s model allows replayability, which permits multiple independent applications that read data streams to operate independently at their own pace.